SQL Server 2016 brings new kind of reports – Mobile Reports which are DataZen product integrated into SQL Server 2016.
It brings many new possibilities but also some pitfalls a user must be aware when developing reports.
Time Navigator Parameters Problem
One of those pitfalls is a Time Navigator if you want to use it for passing dynamic query parameters. It works correctly if you have a local time zone set to UTC (but nobody is using that time zone). The problem appears if you start to use it with different local time zones and need to pass the selected date ranges to Shared Dataset for dynamic query processing.
The problem is that Time Navigator is providing the SelectedStartTime, SelectedEndTime, ViewportStartTime and ViewportEndTime as UTC Date/Time Strings. This means in the yyyy-MM-ddThh:mm:ss.fffZ format eg. 2016-01-01T00:00:00.000Z. This itself would not be a problem but problem is that the report client is automatically shifting the selected range by the current user Time Zone offset including the daylight saving time at the selected date.
If your current time zone would be UTC where everything works properly then For example if you select in the Time Navigator a date 2016-01-01, the SelectedStartTime will provide 2016-01-01T00:00:0Z and SelectedEndTime will provide 2016-01-02T00:00:00.000Z. This is OK as you proces that information on the Server as interval <2016-01-0100:00:00Z; 2016-01-02T00:00:00.000Z).
However if you are in different time zone, as it was mentioned above, the provided stamps are shifted by the current time zone including a daylight saving. This means if you would be in UTC+1 the SelectedStartTime will provide 2015-12-31T23:00:00Z and SelectedEndTime will provide 2016-01-01T23:00:00Z.
In case of UTC-6 SelectedStartTime will provide 2016-01-01T06:00:00Z and SelectedEndTime will provide 2016-01-02T06:00:00Z.
As you can see, in case you are developing a report for users within single time zone, this would not be a big problem as you can deal with that. However if you are developing reports for enterprise users and the requests are arriving from different time zones, you always receive different time stamps. What more, in the time stamp there is no information about the originating time zone as the parameter is sent as plain string. The biggest issue of that is that because of that time shift handled on the user side, you may receive different start and end dates from what user selected.
Problem Demo
Let’s create an easy demonstration of that problem. Create a new Mobile Report, place a Time Navigator on the surface and in the Time intervals include Years, Months, Days.

Then we need to create a testing Data Set on the Server. Let’s create a very simple Data Set, which will simply return the passed Start Date and End Date back to the client including the information about the parameter.
DECLARE @type sql_variant = @StartDate;
SELECT
@StartDate AS StartDate
,@EndDate AS EndDate
,@Unit AS TimeUnit
,SQL_VARIANT_PROPERTY(@type, 'BaseType') AS StartDateDataType
We are adding the @type sql_variant to see what kind of data type is arriving to SQL Server. As we are creating a parameterized Data Set which will be used by Mobile Report, you have to set a default values for the parameters.


Once we have the Data Set ready, add it into the Mobile Report and Set the Parameters Binding.

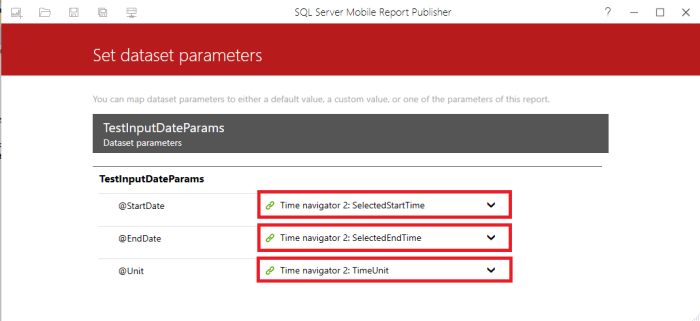
After that we can add a Data Grid to the design surface which will show us the passed parameters.
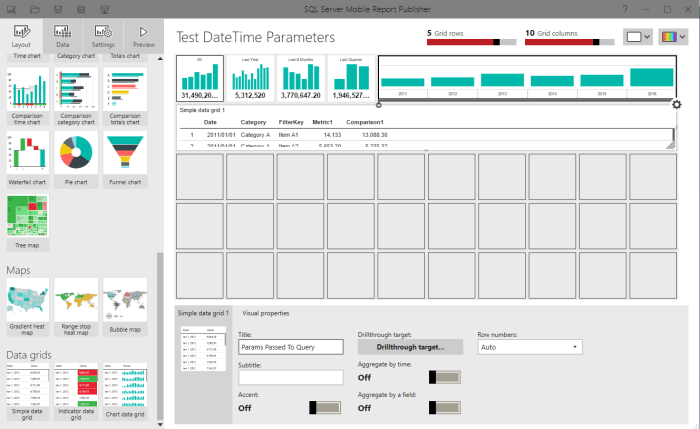
And Bind it to our parameterized Data Set

Testing the Parameters
Once we have the testing report ready, we can start playing with it to demonstrate the problem.
UTC
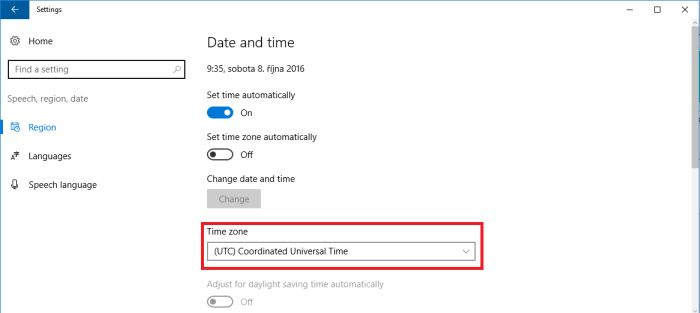
First let’s check how it looks when the report is being run in the (UTC) Coordinated Universal Time.
Head to the Settings and se the UTC Time Zone. Also note that the UTC does not allow adjusting for daylight saving time.
And the Result is here:

We can clearly see, that for the whole year 2015 period the Start Date was passed as 2015-01-01T00:00:00.000Z and the end date was passed as 2016-01-01T00:00:00.000Z. This is correct and expected values which should be received. We also see, that we have received the parameter as nvarchar, this means plain string.
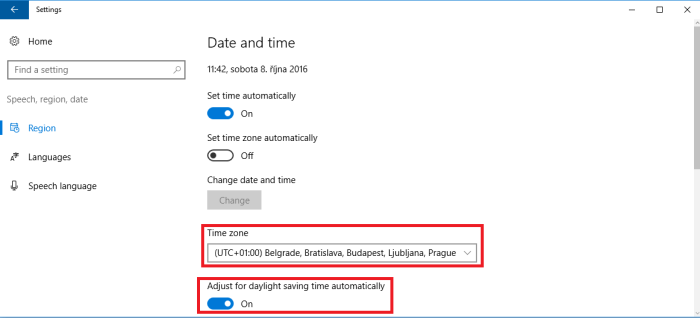
UTC+1
Now head again to settings and switch the Time Zone to some of the UTC+1 zones. And Ensure, that you also select one with automatic daylight saving time
And Let’s make some tests.
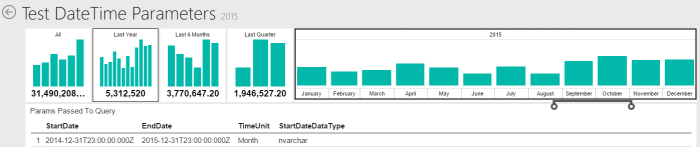
Here we can see, that for the whole year 2015 both the Start Date and End Date was shifted by the zone offset. So now we received the Start Date as 2014-12-31T23:00:00.000Z and End Date as 2015-12-31T23:00:00.000Z.
Now Select some month where the daylight saving is in effect. For example June.

Here we can see, that the dates were shifted by the time zone offset as well the daylight time saving amount, this means shifted by 2 hours. The result is that Date Start was passed as 2015-05-31T22:00:00.000Z and End Date was passed as 2015-06-30T22:00:00.000Z.
Let’s take a look on different month during which the daylight saving change occurs, for Example March.

Here we can clearly see, that the Start Date is shifted by one hour as the daylight saving was not in effect however the End Date is shifted by 2 hour as the daylight saving was on during that time. So Results are for Start Date 2015-02-28T23:00:00.000Z and End Date 2015-03-31T22:00:00.000Z.

The same behavior we can see during the day to which the daylight saving went into effect. In case of year 2015 it was March 29. In that case we receive Start Date 2015-03-28T23:00:00.000Z and End Date 2015-03-29T22:00:00.000Z
UTC-6
Again head to the settings and adjust the time zone to TUC-6, e.g. Central Time.

And repeat some tests

Here we can see, that the dates were again shifted. This time the oposit way compared to the “plus” time zones. So for the whole year 2015 the Date Start we have 215-01-01T06:00:00.000Z and End Date as 2016-01-01T06:00:00.000Z.
As mentioned the same behavior we would see for all the tests.
Dealing with the issue
Ad mentioned at the beginning of that post. In case you develop a report which will use only users in one time zone and you know that those users are not travelling to different time zones when consuming the report the problem is not so big. as you adjust your eventual parameters processing for your time zone.
However if you develop an enterprise solution when the reports are using users around the globe from different time zones, you have to count with that. As it is clearly visible, you can receive different dates for different Time Zones.
As we saw from the test. in case for the Whole year of 2015 we receive
From that if you focus on whole dates, you can for example shift the dates by +1 in case eg. the Time Part of the received Start/End date string is for example greater or equal to 12:00:00 pm and do nothing with that parameter is the Start/End Date is till 12:00:00 pm.
No 100 % bullet proof solution
This will work for most common scenarios, but is not 100 % bullet proof if you have report users in time zones in more that +12. In case you would have users in +13 or +14 time zone and at the same time users in the -11 time zone, then there is no solution for such situation in case you go to the day level.
Let’s take a look a on a situation when use from UTC+14 (Kiritimati Island) time zone selects date 2015-01-05:
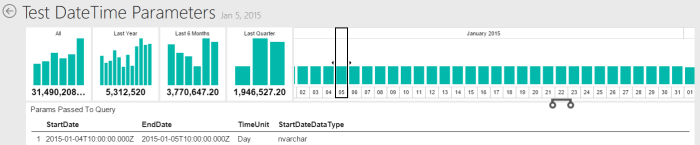
Date Start is 2015-01-04T10:00:00.00Z and Date End is 2015-01-05T10:00:00.00Z
And now another users in the UTC-10 (Hawaii) selects a date 2015-01-04:
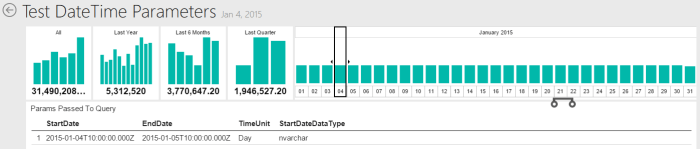
Here we again receive Date Start 2015-01-04T10:00:00.000Z and Date End 2015-01-05T10:00:00.000Z.
Because no information about the originating time zone of the user running the report is being passed to the date set on the report server and underlying database, we are not able to distinguish between those two different cases.
I can imagine a scenario in which this behavior would be useful, but in most cases this is not a wanted functionality. There is no setting in the report or report server to enable/disable this behavior and the report developer has to be very careful about that.






{kind=link}